About this project
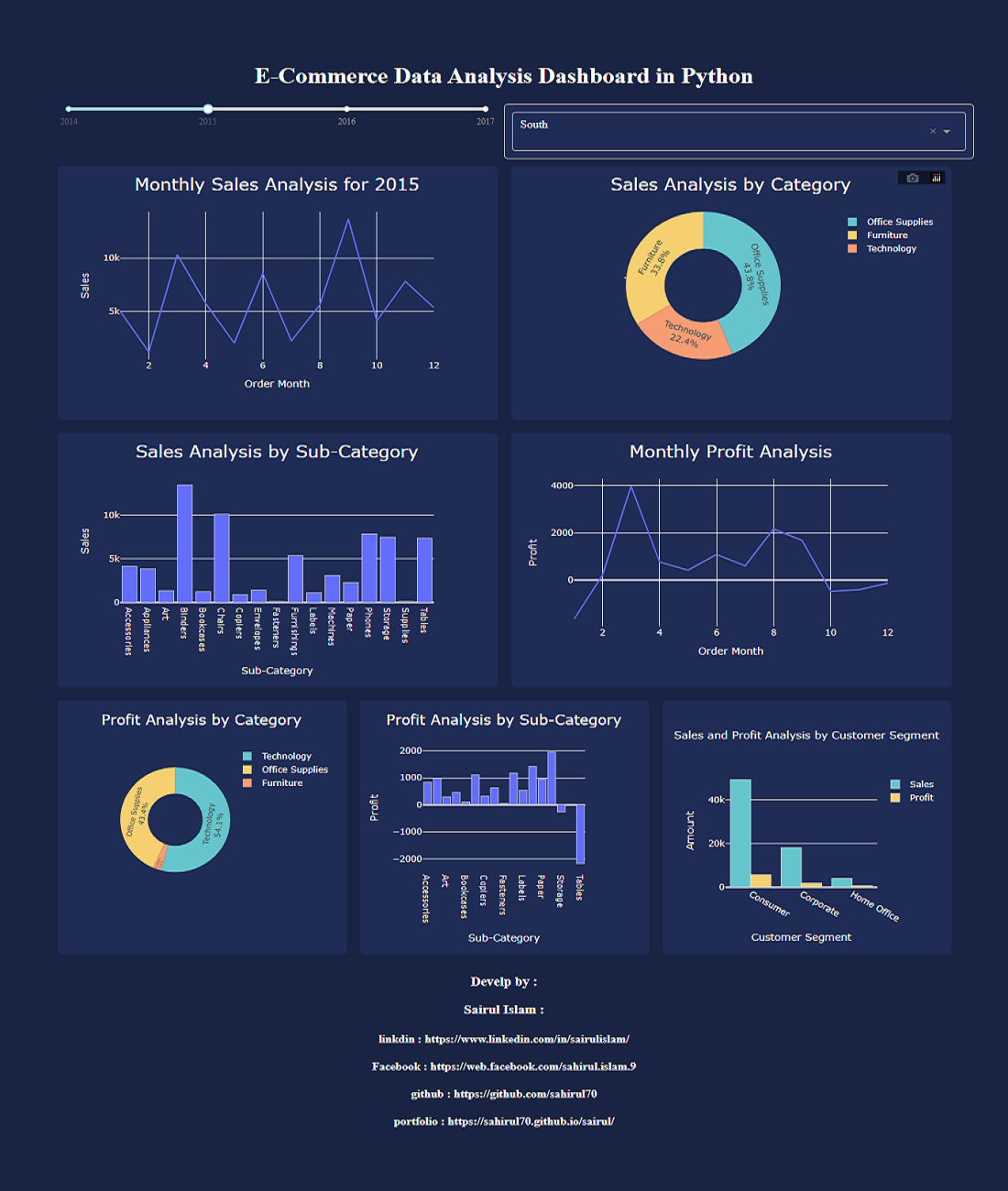
Dataset Description
The dataset combines HR data (attrition, employees) and operational performance data
(delivery & preparation work). It is likely sourced from HRIS (Human Resource Information Systems),
Project Management Tools, and Operational Logs.
Work Process
Data & labeling
Collect fruit images (field photos + web). Target classes: e.g., apple, banana, orange, grape, strawberry, pear…
Label with LabelImg/Roboflow → YOLO format (.txt per image: class x_center y_center width height normalized 0–1).
Split train/val/test (e.g., 70/20/10). Add augmentations (flip, HSV, mosaic, blur) to handle lighting and occlusion.
Model training (YOLOv9)
Prepare a data.yaml (paths, class names, counts).
Start from yolov9s/l pretrained weights.
Typical args: img=640, batch=16, epochs=100–300, lr=0.01, optimizer=SGD or AdamW.
Monitor mAP@0.5 / mAP@0.5:0.95, precision/recall, and loss curves; early stop on plateau.
Evaluation & export
Validate on the test set; tune conf (e.g., 0.25–0.35) and NMS IoU (0.5) for best trade-off.
Export weights to best.pt (or ONNX/TensorRT if needed).
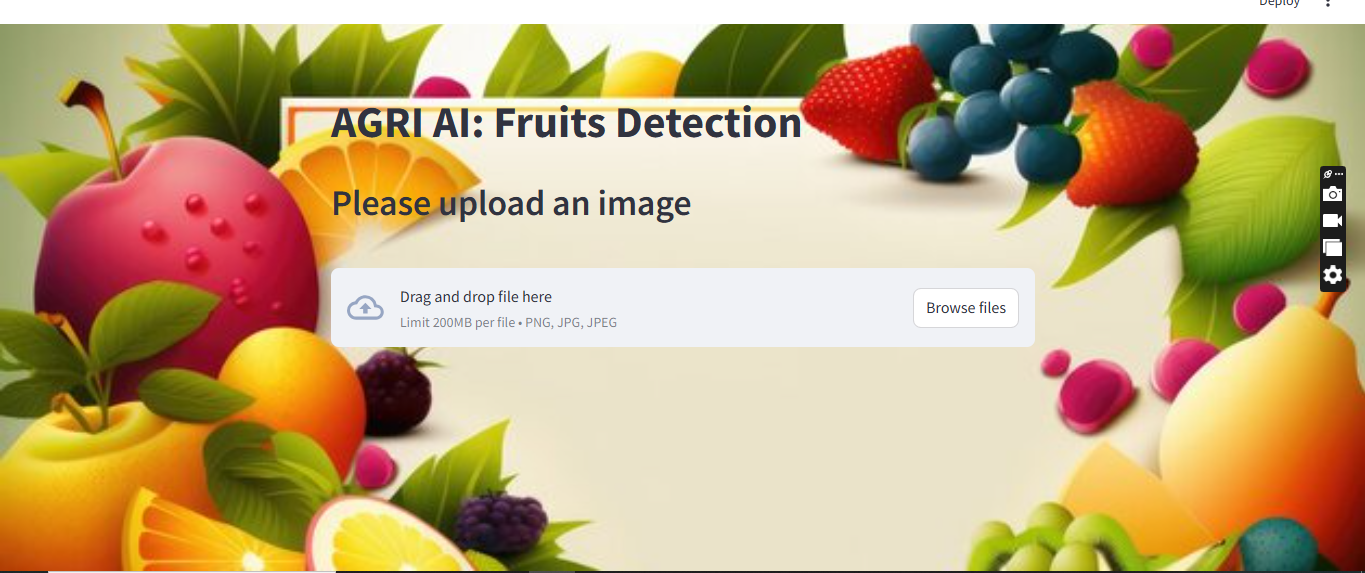
Streamlit app (backend inference)
streamlit UI: file uploader → image bytes → preprocessing.
Load best.pt once (cache). Run inference, draw boxes/labels/scores, return image.
Optional: show per-class counts, latency, confidence slider.
Folder sketch:
app.py / models/best.pt / data/ / utils/ / requirements.txt
Deployment
Local: streamlit run app.py.
Cloud: Streamlit Community Cloud / Docker on VM; set torch + opencv-python-headless deps; use CPU or CUDA.
✅ Summary:
This project builds a real-time fruit detector using YOLOv9 trained on a custom labeled dataset,
wrapped in a Streamlit interface for easy image upload and visualization. The pipeline covers data curation,
robust annotation, transfer-learning-based training, quantitative validation (mAP/precision/recall), and a lightweight web app
for inference. Users drag-and-drop a photo and instantly see bounding boxes and class names, enabling quick quality checks or
automated counting in agricultural workflows. For next steps, consider: adding more orchard conditions, model pruning/quantization
for edge devices, and a batch API to process folders or video streams.
github